
What Is Video Extraction Infrastructure for AI Teams
Video extraction infrastructure is defined as the end-to-end backend system that ingests raw video, processes it through AI models, and delivers structured data outputs to downstream automation and analysis workflows. It is not a single tool. It is a pipeline of coordinated components: ingest handlers, frame extractors, inference engines, orchestration layers, and delivery mechanisms. Organizations building AI video tools, transcription platforms, or training datasets depend on this infrastructure the same way they depend on databases or message queues. Without it, video content stays locked in binary files, inaccessible to any intelligent system.
What is video extraction infrastructure, and how is it structured?
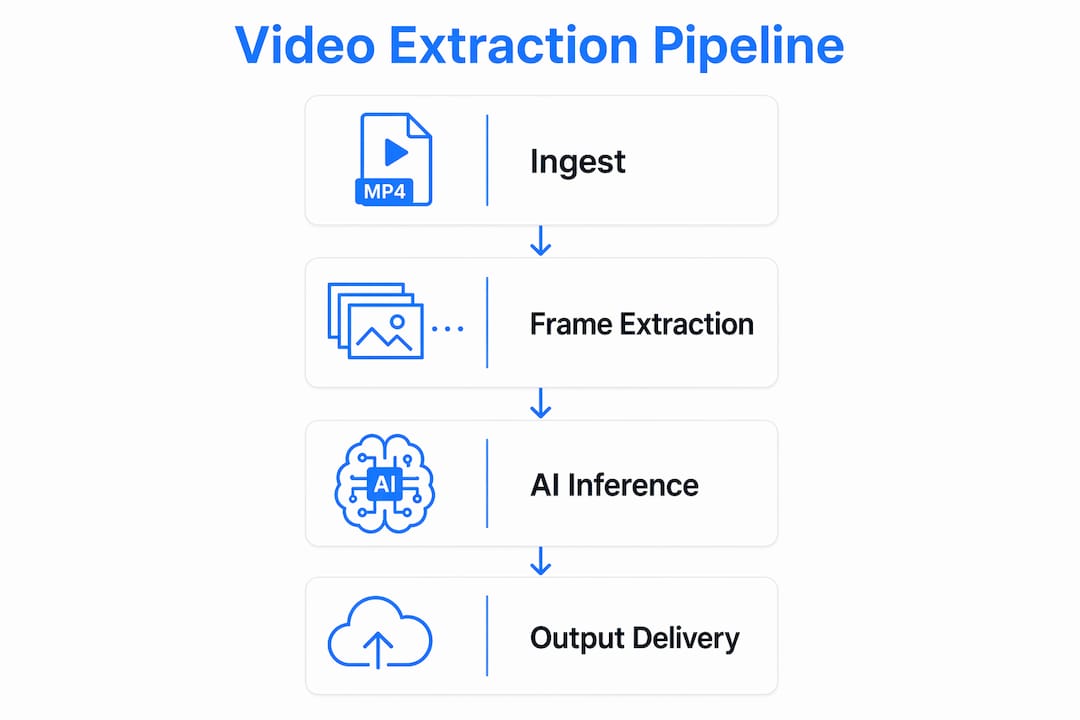
Video extraction infrastructure processes video through four distinct stages: ingest and stream capture, frame extraction and preprocessing, AI model inference, and structured output delivery. Each stage has its own failure modes, latency profile, and engineering requirements. Understanding the full chain is what separates teams that ship reliable AI video products from teams that spend months debugging flaky pipelines.
The ingest layer accepts video from multiple sources: direct file uploads, URL fetches from platforms like YouTube or TikTok, and live stream capture. Format normalization happens here. A video arriving as an MKV container with AV1 encoding must be converted to a format that downstream workers can process without errors. Tools like FFmpeg handle this conversion reliably at scale.

Frame extraction and preprocessing follow ingest. The system samples frames at defined intervals or on scene-change triggers, resizes them to model-compatible dimensions, and normalizes pixel values. This stage determines the granularity of your temporal data. Sample too infrequently and you miss critical events. Sample every frame on a 4K 60fps source and you generate compute costs that make the pipeline uneconomical.
AI model inference runs on the extracted frames and audio tracks. Common models include OCR for on-screen text, object detection for product or entity recognition, action recognition for behavioral classification, and ASR (automatic speech recognition) for transcription. Each model produces outputs tied to a timestamp, which is the key artifact that makes video data useful for automation.
Pro Tip: Design your inference layer to run OCR, object detection, and ASR in parallel rather than sequentially. On a 10-minute video, parallel inference can cut total processing time by 60% compared to a sequential chain.
The final stage delivers structured outputs, typically JSON, via webhook POST or API response to ticketing systems, CRMs, or training pipelines. Webhook-first architecture is the production standard because it decouples extraction latency from the calling application's response cycle.
How does video extraction handle streaming formats like HLS?
Streaming video presents a fundamentally different engineering problem than file-based extraction. HLS (HTTP Live Streaming) does not deliver a single file. It delivers a playlist file (.m3u8) that references dozens or hundreds of short transport stream segments (.ts files), each typically 2 to 10 seconds long. Your infrastructure must understand this structure before it can extract anything useful.
The standard approach for HLS extraction fetches the master playlist, parses the variant streams to select the appropriate quality level, downloads the .ts segments in order or in parallel, and then muxes them into a single MP4 container using FFmpeg's remux mode. Remuxing copies the encoded bitstream without re-encoding, which preserves quality and runs significantly faster than transcoding.
Three specific challenges make HLS extraction harder than it looks:
- Encrypted segments: Many platforms use AES-128 encryption on .ts segments. Your fetcher must retrieve the decryption key from the key URI in the playlist and apply it during segment download, not during muxing.
- Codec compatibility: HLS streams sometimes carry HEVC or AV1 video with AAC or Opus audio. Not every downstream model or container supports every codec combination. Your normalization step must detect and handle these cases explicitly.
- Playlist staleness: Live streams update their playlists continuously. A segment fetcher that does not poll for new segments at the correct interval will miss content or stall.
Video extraction pipelines must be designed to handle the complexity of modern streaming formats and encryption schemes to ensure reliable data outputs. Source
Extraction latency is dominated by data movement and storage I/O, not by encoding settings. A pipeline that writes each segment to disk before muxing will be slower than one that pipes segment bytes directly into the muxer's stdin. Zero-storage pipe architectures, where segments flow from network to muxer to output without intermediate disk writes, are the correct design for latency-sensitive applications. For a deeper look at handling podcast and streaming formats specifically, the podcast extraction developer guide covers segment reassembly in practical detail.
What data does video extraction infrastructure produce for AI workflows?
The outputs of a video extraction system fall into two categories: technical metadata and semantic data. Most teams underestimate how different these are and how each serves a distinct purpose in an AI workflow.
Technical metadata comes from tools like FFprobe and describes the container: codec, duration, resolution, bitrate, frame rate, and audio channel layout. This data is necessary for pipeline routing decisions but carries no semantic meaning for AI models or business logic.
Semantic data is what extraction for AI use cases actually requires. It includes OCR text from on-screen graphics, product labels identified by object detection models, damage severity tags from classification models, speaker diarization results from ASR, and action labels from temporal activity recognition. Each output is mapped to a timestamp, creating a time-indexed record of everything that happened in the video.
| Output type | Example | Downstream use |
|---|---|---|
| OCR text | "Price: $49.99" at 00:02:14 | Product catalog enrichment |
| Object detection | "Cracked windshield" at 00:00:47 | Insurance claim automation |
| ASR transcript | Speaker 1 segment, 00:01:05 to 00:01:38 | CRM call logging |
| Action recognition | "Fall detected" at 00:03:22 | Safety incident ticketing |
| Technical metadata | 1080p, H.264, 29.97fps | Pipeline routing, storage tiering |
Structured JSON outputs with timestamp alignment are the delivery format that makes this data actionable. A JSON payload containing an OCR result, its bounding box, its confidence score, and its timestamp can be mapped directly to a custom schema field in Salesforce, Zendesk, or any internal QA system. This schema mapping step is where video extraction connects to real business value.
Pro Tip: Build your JSON schema before you build your extraction pipeline. Defining the exact fields your CRM or ticketing system expects forces clarity on which AI models you actually need, and prevents scope creep during implementation.
For teams building AI training datasets, the video training dataset guide explains how to use time-aligned extraction outputs as labeled training examples at scale.
How can organizations deploy video extraction infrastructure effectively?
Production-grade video extraction infrastructure is always decoupled. A monolithic service that ingests, processes, and delivers in a single synchronous call will fail under load and make debugging nearly impossible. The correct architecture separates each stage behind a message queue.
A proven pattern uses 1MB chunked uploads to object storage (S3, R2, or GCS), a Kafka message queue to signal worker pools, FFmpeg transcoding workers that pull jobs from the queue, Redis for caching job state, and CDN distribution for output delivery. This architecture scales horizontally. Adding workers increases throughput without changing any other component.
Cloud and edge deployment each serve different requirements:
- Cloud deployment on AWS with services like Kinesis Video Streams and OpenSearch suits centralized analytics workloads where latency above 5 seconds is acceptable and data sovereignty is not a constraint.
- Edge deployment using AWS IoT Core and Kinesis Video Streams suits manufacturing floors, retail locations, or healthcare settings where data must stay on-premises and inference latency must stay under 500 milliseconds.
Security is not optional at any scale. Signed URLs with short expiry windows protect video assets in object storage. Webhook payloads must include HMAC signatures so receiving systems can verify authenticity. Encryption in transit (TLS 1.3) and at rest (AES-256) are baseline requirements for any enterprise deployment. The webhooks deep dive covers HMAC validation patterns and retry logic in detail.
Effective video extraction infrastructure combines AI model outputs with orchestration layers managing device state, configurations, and remote operations. The orchestration layer is what most teams underestimate. It handles job retries, dead-letter queues for failed extractions, model version management, and output schema versioning. Without it, a pipeline that works in staging breaks silently in production.
Key takeaways
Video extraction infrastructure requires a decoupled pipeline of ingest, inference, and delivery components to produce reliable, structured data from raw video at production scale.
| Point | Details |
|---|---|
| Four-stage pipeline | Ingest, frame extraction, AI inference, and structured delivery are the four non-negotiable stages. |
| HLS requires custom handling | Segment fetching, decryption, and muxing must be built explicitly; streaming players do not expose this logic. |
| Semantic data beats metadata | OCR, object detection, and ASR outputs tied to timestamps are what AI workflows actually consume. |
| Decoupled architecture scales | Message queues between stages allow horizontal scaling and isolate failures to single components. |
| Latency lives in I/O | Pipeline design choices like parallel uploads and zero-disk-write paths matter more than codec settings. |
Why most teams get video extraction wrong on the first build
I have seen the same mistake repeated by otherwise strong engineering teams: they treat video extraction as a transcoding problem. They stand up FFmpeg, pull a video, convert it to MP4, and call it infrastructure. Then they discover that their AI models need frame-level timestamps, their CRM expects a specific JSON schema, their source platform rotates anti-bot measures weekly, and their pipeline has no retry logic for failed segment fetches. The rebuild takes longer than the original build.
The harder truth is that the orchestration layer is the actual product. The ML models are commodities. OCR from Google Cloud Vision, ASR from Whisper or AssemblyAI, object detection from a fine-tuned YOLO variant: these are solved problems you can drop in. What is not solved out of the box is the state management, the schema mapping, the webhook delivery guarantees, and the anti-bot handling for platform-sourced video. That is where the engineering time actually goes.
Edge deployment is the trend I find most underappreciated right now. Privacy regulation in healthcare and finance is pushing extraction workloads to on-premises hardware faster than most cloud vendors anticipated. A hospital system cannot send surgical video to a public cloud endpoint. A financial institution cannot stream trading floor footage through a third-party API. The teams building edge-capable extraction infrastructure today are positioning themselves for a regulatory environment that will make cloud-only pipelines untenable in regulated industries within three years.
My practical advice for any technology leader evaluating this space: do not evaluate tools in isolation. Evaluate the full operational surface. Ask the vendor what happens when a segment fetch fails at position 47 of 200. Ask what the retry policy is. Ask how schema changes are versioned. The answers will tell you whether you are buying infrastructure or buying a prototype.
— Alexandre
Build on production-grade video extraction infrastructure with Tornadoapi
Tornadoapi is the video extraction infrastructure built specifically for AI teams and content workflows at scale. One API call handles anti-bot systems, proxy rotation, format normalization, and direct cloud delivery to S3, R2, GCS, or Azure. Tornadoapi delivers 300 TB per month with 99.998% extraction reliability measured in production, backed by a contractual SLA. Frontier AI labs, transcription SaaS platforms, and podcast networks use Tornadoapi to replace unmanaged scraping toolboxes with a single, reliable extraction layer. If your team is evaluating production-scale extraction tiers, the plans page covers volume thresholds and enterprise options. For an infra-to-infra conversation, book a 30-minute call at cal.com/velys/30min.
FAQ
What is video extraction infrastructure in simple terms?
Video extraction infrastructure is the backend system that takes raw video files or streams, runs AI models on them, and delivers structured data like transcripts, object labels, and timestamps to downstream applications via APIs or webhooks.
How does video extraction differ from transcoding?
Transcoding produces container metadata like codec and resolution, while extraction produces semantic AI outputs such as OCR text, detected objects, and speech transcripts aligned to timestamps. They solve different problems.
What formats does video extraction infrastructure support?
Production systems handle MP4, MKV, WebM, and streaming formats like HLS (.m3u8 with .ts segments). HLS requires custom segment fetching and muxing logic that standard media players do not expose.
Why does extraction latency matter more than encoding speed?
Latency is dominated by data movement and storage I/O, not codec parameters. Pipeline architecture choices like parallel segment fetching and zero-disk-write paths have a larger impact on time-to-output than encoder settings.
What are the benefits of a decoupled extraction pipeline?
Decoupled pipelines using message queues like Kafka allow each stage to scale independently, isolate failures, and support retries without affecting other components. This is the architecture pattern used by billion-scale video systems.