
Why Batch Video Downloading Fails Without Infrastructure
Most developers hit the same wall. They write a script, queue up a few hundred videos, and watch it die somewhere around request 50. They swap libraries, rotate cookies, change user agents, and it still fails. The reason why batch video downloading fails without infrastructure is almost never the code. It's everything underneath the code. Platform defenses operate at the network layer, not the application layer, and no amount of header tweaking changes what your IP address tells a server before your request is even read.
Table of Contents
- Key takeaways
- Why batch video downloading fails at scale without infrastructure
- Naive approaches versus production-grade infrastructure
- Common misconceptions about overcoming batch download failures
- Practical infrastructure strategies for reliable batch downloads
- My honest take on where developers go wrong
- How Tornadoapi solves this at production scale
- FAQ
Key takeaways
| Point | Details |
|---|---|
| IP reputation blocks before auth | Datacenter IPs get flagged at the network level before cookies or headers are ever checked. |
| Error codes signal specific needs | A 429 error needs a 1 to 5 minute back-off; a 503 can require up to 120 minutes before retrying. |
| Blind retries increase cost and risk | Retrying 500 or 504 errors without checking status first creates duplicate workloads and potential bans. |
| Residential proxies are non-negotiable | Routing through residential IPs is the only practical way to make batch downloads appear as normal user traffic. |
| Async architecture handles scale | Frameworks like Python Asyncio combined with Redis state management are what separate stable pipelines from fragile scripts. |
Why batch video downloading fails at scale without infrastructure
The single biggest misconception in batch video download issues is that platform blocking is a software problem. It is not. Datacenter IPs are flagged at the network level by IP reputation databases, and that evaluation happens before your request body, cookies, or user-agent string are ever examined. You can perfectly mimic a Chrome browser session and it will not matter. The server already decided what to do with your traffic the moment it saw your IP's ASN.
This is why so many developers waste weeks on application-layer fixes. The solutions feel logical. Rotate cookies. Spoof headers. Add random delays between requests. Each of those things has a place, but none of them address the root cause of why batch downloads fail at scale.
Here is what is actually happening at the network layer:
- IP reputation scoring. Major platforms maintain or subscribe to databases that classify IPs by origin. Residential IPs score as legitimate users. Datacenter ranges from AWS, GCP, and Azure score as bots by default, regardless of your request behavior.
- Rate limiting via HTTP status codes. A 429 error requires a 1 to 5 minute back-off before retrying. A 503 can demand up to 120 minutes. Most batch scripts treat these as generic errors and retry immediately, which accelerates the path to a permanent block.
- CAPTCHAs and challenge pages. These trigger not on suspicious request content but on traffic patterns and IP reputation scores. By the time you see a CAPTCHA, the platform has already flagged your session.
- Session fingerprinting. Platforms track behavioral signals across a session: scroll events, mouse movement timing, page load sequences. Programmatic access lacks all of these, and no static header can fake them convincingly at volume.
Pro Tip: Before writing any retry logic, build status-code-aware handling first. A script that knows the difference between a 429 and a 503 and waits accordingly will outlast one that retries blindly by orders of magnitude.
Naive approaches versus production-grade infrastructure
There is a large gap between "a script that downloads videos" and "a system that downloads videos reliably at scale." Understanding that gap is how you stop chasing fixes that do not work.
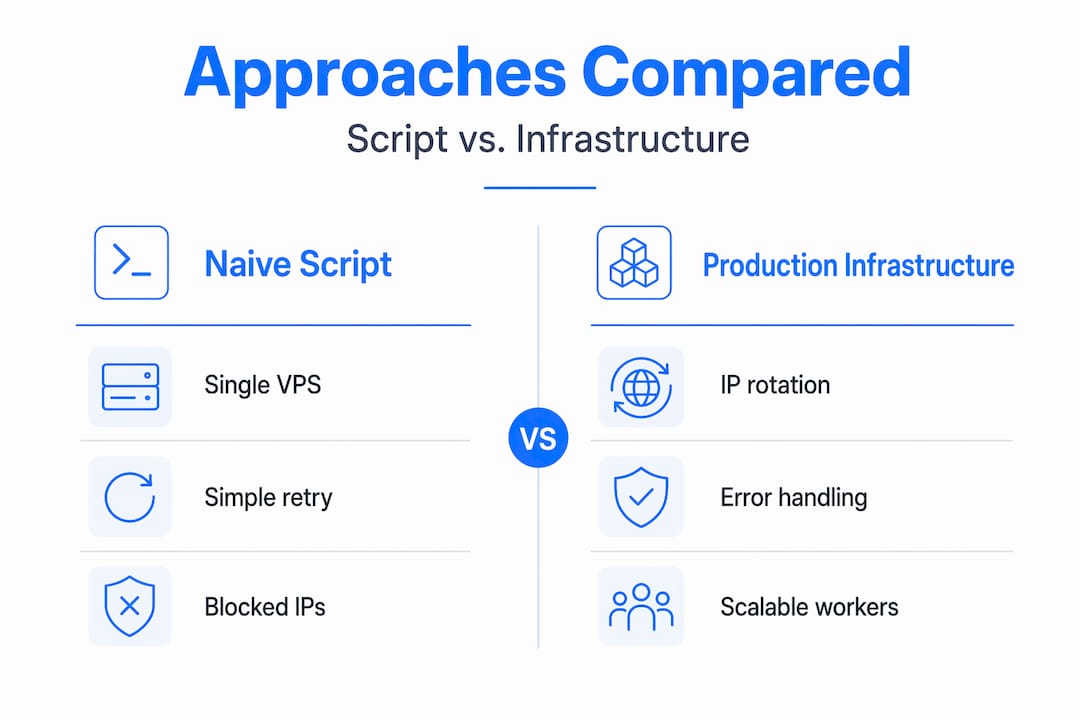
The table below shows exactly where naive approaches break down compared to what production infrastructure requires:
| Component | Naive approach | Production requirement |
|---|---|---|
| IP management | Single datacenter VPS | Residential proxy pool with rotation |
| Concurrency | Synchronous requests | Async workers with queue management |
| Storage | Local disk or single cloud bucket | Scalable media storage with CDN offload |
| Error handling | Generic retry on any failure | Status-code-aware back-off with deduplication |
| State management | None or basic logging | Redis or equivalent for download state tracking |
| Transcoding | Post-download manual step | Scalable transcoding workers integrated in pipeline |
A regular cloud VPS using datacenter IP space will get blocked fast. This is not a maybe. It is the default outcome. The video downloading infrastructure needs to begin with residential proxy routing, not as an add-on but as the foundation.

One failure mode that catches teams off guard is the "thundering herd" effect. When viral content spikes, many workers attempt to download the same resource simultaneously. Without queue management and deduplication, you get hundreds of identical requests hitting a platform within seconds. That pattern triggers automated abuse detection faster than almost anything else.
High-volume video processing also requires transcoding workers, scalable media storage, and CDN offload to avoid latency spikes during peak loads. Building those pieces individually takes significant time and operational overhead.
Pro Tip: Treat your download infrastructure the same way you would treat a payment processing system. Every component needs a fallback, every error needs a defined response, and nothing should be stateless.
Common misconceptions about overcoming batch download failures
The amount of bad advice circulating about batch video download failures is significant. Some of it is outdated. Some of it was never correct. Here are the ones that cause the most damage:
- "Rotating user agents is enough." Platforms stopped caring much about user agents years ago. What they care about is IP reputation, behavioral signals, and session fingerprinting. A fake user agent string on a datacenter IP is still a datacenter IP.
- "Third-party download tools solve the problem." Many popular download tools are repackaged without active maintenance, which creates two problems. First, they break constantly because platform cipher and signature formats change frequently. Second, tools sourced from unofficial channels carry real security risks including malware. Both issues compound over time in a production environment.
- "Platform restrictions are consistent and predictable." They are not. Platforms update their extraction defenses regularly, sometimes weekly. A tool that worked reliably in Q1 may be completely broken by Q3 with no announcement. Any strategy that relies on a static implementation will fail eventually.
- "More aggressive retrying will push through failures." This is the most costly misconception. Blind retries on 500 and 504 errors create duplicate workloads and doubled costs without any improvement in success rate. Worse, the pattern itself can trigger automated abuse detection.
- "A VPN is equivalent to residential proxies." Consumer VPNs exit through datacenter IPs. From a platform's perspective, your traffic looks identical to any other bot on datacenter infrastructure.
The video download failures explained by each of these misconceptions have one thing in common: they focus on disguising the application layer while ignoring the network layer. That inversion is the core mistake.
Practical infrastructure strategies for reliable batch downloads
Getting batch video downloading to work reliably at scale requires four things working together. They are not optional additions. They are the floor.
-
Residential proxy routing. Routing through residential IPs is the only practical method to disguise the datacenter origin of your workers. The requests appear as normal user activity because the exit IP is genuinely residential. This is the first thing to build, not the last.
-
Asynchronous batch processing with intelligent retry logic. Python Asyncio combined with Redis gives you the state management needed to handle rate limits and concurrency without losing track of download status. Every job needs a state: queued, in-progress, completed, failed. Without that, retries create chaos.
-
Scalable transcoding workers and CDN offload. Hyper-distributed delivery architecture with many points of presence handles concurrency spikes far better than a single large node. Your transcoding layer needs to scale horizontally with demand, not vertically with a bigger machine.
-
Managed video extraction APIs. For most teams, building all of the above in-house is a significant multi-month project. Production-grade services designed specifically for video extraction at scale handle proxy rotation, anti-bot evasion, format normalization, and direct cloud delivery as a single API call. The infrastructure for video downloads is already built. You consume it.
The following table maps common failure symptoms to the infrastructure component that resolves them:
| Failure symptom | Root cause | Infrastructure fix |
|---|---|---|
| Blocked after 50 requests | Datacenter IP flagged | Residential proxy pool |
| 429 errors with no recovery | No back-off logic | Async rate-limit-aware retry |
| Duplicate downloads on retry | No state management | Redis job state tracking |
| Latency spikes at peak load | No CDN or transcoding layer | Scalable workers plus CDN offload |
| Tool breaks after platform update | Unmaintained extraction logic | Actively maintained extraction API |
Pro Tip: Build your retry logic as a first-class feature, not an afterthought. Define a maximum retry count, exponential back-off intervals for each error code, and a dead-letter queue for jobs that exhaust all retries. That pattern alone will save you more production incidents than almost any other single decision.
My honest take on where developers go wrong
I've watched a lot of teams burn weeks on the wrong layer of the problem. The pattern is almost always the same. A developer writes a working prototype, it breaks at scale, and the instinct is to patch the code rather than reconsider the architecture.
What I've learned from seeing this play out repeatedly is that network-layer IP reputation is the hardest thing for developers to internalize because it is invisible. Your code looks fine. The requests look well-formed. But the platform made its decision before the first byte of your request body was read. That invisibility makes it easy to keep blaming the application code.
The platforms are also not standing still. Every major video platform has meaningfully raised the technical bar for extraction in the past two years. Cipher rotations, JavaScript challenge pages, behavioral fingerprinting. What worked in 2023 may require a full rewrite today. The teams that try to keep pace with those changes in-house almost always underestimate the ongoing maintenance cost.
My honest advice: treat the download infrastructure as a cost center with an explicit budget, not as a one-time build. If your budget and timeline do not support building residential proxy rotation, async state management, and active platform monitoring from scratch, find infrastructure that already does it. The challenges of batch downloading at scale are real, and they compound. Chasing quick fixes costs more in the long run than getting the foundation right the first time.
— Alexandre
How Tornadoapi solves this at production scale
Tornadoapi is built exactly for the failure modes this article describes. It sits between YouTube, Spotify, Instagram, TikTok, and your pipeline, handling anti-bot evasion, proxy rotation, and format normalization so your team writes one API call and gets the file. No proxy pool to manage. No cipher updates to chase.
The batch video extraction API delivers 300 TB monthly at 99.998% reliability with direct cloud export to S3, R2, GCS, and Azure. You can explore scalable pricing tiers sized for everything from a growing SaaS to a frontier AI lab. If you want an infra-to-infra conversation, the team is available at Cal.com/velys/30min.
FAQ
Why do batch video downloads fail on datacenter IPs?
Platforms use IP reputation databases that flag datacenter IP ranges before processing any request content. No application-level spoofing can override this network-layer decision.
What do 429 and 503 errors mean for batch downloading?
A 429 signals rate limiting and requires a 1 to 5 minute back-off before retrying. A 503 can require up to 120 minutes. Retrying immediately on either code typically results in escalating blocks.
Are residential proxies really necessary for batch downloads?
Yes. Residential proxies route your requests through IPs that platforms classify as legitimate users. There is no comparable alternative for avoiding datacenter-level IP blocking at scale.
How does async architecture help with batch video downloading?
Asynchronous frameworks handle concurrent requests, state tracking, and rate-limit-aware retries without blocking. Synchronous scripts stall on every error and cannot manage the job state needed to avoid duplicates or missed retries.
When should a team use a managed API instead of building their own infrastructure?
When the cost of building and maintaining residential proxy rotation, async workers, and active platform monitoring exceeds the cost of a managed service. For most teams doing production-scale extraction, that crossover happens earlier than expected.