
What Does Video API Reliability Mean for Developers
Video API reliability is the measurable consistency of delivering stable, uninterrupted video playback and accurate processing outcomes from start to finish, not just whether an endpoint returns HTTP 200. For developers building video integrations, this distinction matters enormously. A system can report 99.9% uptime while users experience buffering, failed startups, and broken transcoding jobs. The real measure lives in viewer-centric metrics: startup success rate, rebuffer ratio, time to first frame, and webhook delivery accuracy. Tools like multi-CDN routing, SLA-backed platforms such as Gumlet, and event systems like Wistia webhooks each address different layers of this problem.
What does video API reliability mean vs. general API uptime?
Video API reliability is defined as end-to-end delivery consistency from upload through processing job completion confirmed by webhook events, not just synchronous HTTP request success. This is the sharpest distinction between video API reliability and traditional API reliability, and most developers learn it the hard way.
Standard API reliability focuses on infrastructure availability: is the server responding, and is the error rate below a threshold? Video APIs add a second dimension entirely. The API can respond successfully to every request while the transcoding pipeline stalls, the CDN edge node serves a corrupted segment, or the player never receives the webhook confirming job completion.

The industry separates these two dimensions into Quality of Service (QoS) and Quality of Experience (QoE). QoS covers infrastructure uptime, error rates, and latency at the network layer. QoE covers what the viewer actually experiences: time to first frame, rebuffering frequency, playback stability, and adaptive bitrate behavior. Video startup time and rebuffering frequency are the strongest predictors of user dissatisfaction and trust in streaming services. That means a QoS-only view of reliability actively misleads you about the health of your video product.
Common Service Level Objectives (SLOs) used in streaming engineering reflect this QoE focus:
- Startup success rate: percentage of playback attempts that reach first frame within a target threshold (typically under 3 seconds)
- Rebuffer ratio: total rebuffering time divided by total viewing time, with thresholds often set below 0.5%
- Recovery time: how quickly the player recovers from a network interruption or segment failure
- Continuity SLO: percentage of sessions completing without a fatal playback error
Evaluating video API reliability requires measuring ingest readiness and playback startup separately, because these represent different reliability perspectives and will rank providers differently depending on your use case.
What factors affect video API reliability in streaming and async workflows?
Video API reliability factors split cleanly into two categories: live streaming infrastructure and asynchronous processing pipelines. Each has distinct failure modes that uptime SLAs do not capture.
For live streaming, low-latency HLS reliability depends on segment durations and packaging strategies that balance latency with caching and rebuffering. Typical LL-HLS configurations use 200 to 500ms parts and require origin-side assembly for stable performance. This means reliability is a packaging-level challenge, not just a network health question. Multi-CDN routing adds another layer: when one CDN edge region degrades, traffic must failover to a secondary provider without the player noticing. Origin server replication and encoding pipeline redundancy sit beneath that. A failure at any layer produces a user-visible event that no uptime metric records.
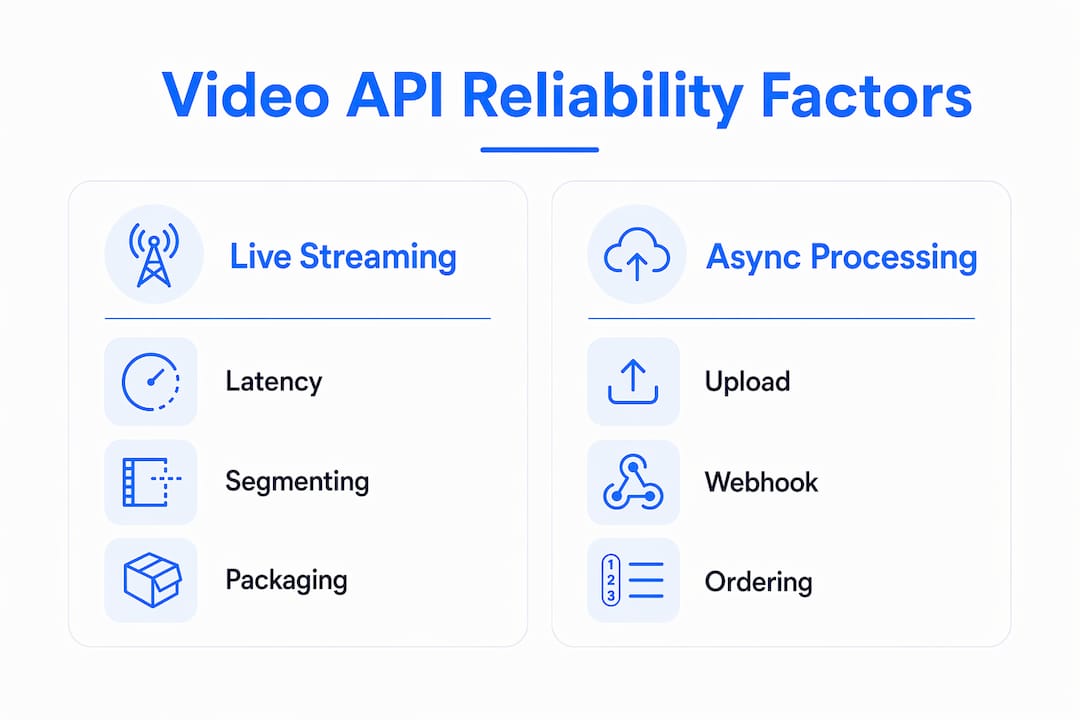
Asynchronous workflows introduce a different class of reliability problem. When a user uploads a video and your system waits for a processing-complete webhook, the reliability of that notification is not guaranteed by the API's HTTP availability. Webhook delivery is at-least-once with possible duplicates and no guaranteed ordering. Consumers must implement idempotency using event UUIDs and timestamps to prevent double-processing or state corruption.
Pro Tip: Design your webhook handler to be ordering-agnostic from day one. A "processing.complete" event arriving before "processing.started" is not a bug in your logic. It is a documented property of distributed event delivery. Use the event UUID to deduplicate and the timestamp to reconstruct sequence.
The practical implication is significant. Failure to implement idempotency and ordering logic leads to hard-to-debug inconsistencies in video processing pipelines. These failures are invisible to infrastructure monitoring because the API responded successfully. They only surface when a user reports a video stuck in "processing" or a duplicate notification triggers a billing event twice.
How to interpret vendor SLAs and reliability claims
99.9% uptime permits approximately 8.7 hours of downtime per year, and vendor SLAs typically focus on infrastructure availability while omitting delivery performance and transcoding pipeline reliability. That number sounds strong until you realize it says nothing about whether your videos transcode correctly, your CDN delivers segments without corruption, or your webhooks arrive.
When evaluating a vendor's reliability claims, the SLA document is the starting point, not the conclusion. The table below maps common SLA components to what they actually cover and what they leave out.
| SLA component | What it covers | What it omits |
|---|---|---|
| Uptime percentage | API endpoint availability | Transcoding success rate, CDN delivery quality |
| Performance commitment | Response time at the API layer | Time to first frame, rebuffer ratio for end users |
| Support tier | Incident response time | Root cause transparency, pipeline failure visibility |
| Redundancy claim | Server or region failover | Encoding pipeline failover, multi-CDN routing |
| Credit policy | Compensation for downtime | No credit for degraded QoE without full outage |
SLA commitments are often narrow. Developers should probe beyond availability numbers to understand performance guarantees for transcoding and delivery quality. Specific questions worth asking any vendor: Does the SLA cover transcoding job failure rates? What is the failover time for CDN region degradation? Does the uptime calculation include partial outages where the API responds but delivery is degraded?
Stream benchmarked scaling WebRTC livestreaming to 100,000 concurrent participants with zero API failures and a 99.999% uptime SLA. That benchmark is useful not because the number is impressive, but because it separates infrastructure uptime from operational API performance under load. Most vendor SLAs never specify the load conditions under which their uptime is measured.
Most reliable video APIs cover the full pipeline: ingest, encode, deliver, analytics, and player with global CDN redundancy and real-time QoE monitoring. Splitting video handling across multiple vendors increases the surface area for failures and makes it harder to assign accountability when something breaks.
How to measure video API reliability in production
Measuring video API reliability in production requires instrumentation at the player layer, not just the server layer. Server logs tell you what the API did. Player metrics tell you what the user experienced. Both are necessary, and neither alone is sufficient.
Real User Monitoring (RUM) for video should capture:
- Startup time: milliseconds from play request to first frame rendered
- Rebuffer ratio: total stall duration divided by total watch time per session
- Error rate by type: distinguishing network errors, DRM failures, and transcoding errors
- Bitrate switches: frequency and magnitude of adaptive bitrate changes as a proxy for CDN instability
- Session abandonment rate: users who leave before first frame, which startup time directly drives
Tools like Mux Data, Conviva, and Datadog's APM layer each approach this differently. Mux Data specializes in video QoE metrics with per-viewer session tracking. Conviva focuses on large-scale streaming analytics with real-time alerting. Datadog covers the infrastructure layer and can correlate server-side events with player-side degradation when instrumented correctly.
Testing before production matters as much as monitoring in production. A/B testing latency versus rebuffer tradeoffs reveals the right balance for your specific audience and content type. Load testing with concurrent stream counts that match your peak traffic exposes encoding pipeline bottlenecks that only appear under pressure. Cross-layer observability, connecting player metrics to CDN logs to origin server traces, is what separates teams that find problems before users do from teams that find out from support tickets.
Automating failover and rehearsing recovery procedures closes the loop. A failover that works in theory but has never been executed under real conditions is not a reliability feature. Schedule quarterly failure drills that simulate CDN region loss, webhook delivery failure, and transcoding pipeline stalls. You can also explore video API rate limit challenges as a related operational concern that compounds reliability issues under load.
Key takeaways
Video API reliability requires end-to-end measurement across ingest, processing, delivery, and event notification layers, with QoE metrics as the primary signal, not infrastructure uptime.
| Point | Details |
|---|---|
| QoE over QoS | Startup time and rebuffer ratio predict user trust better than server uptime percentages. |
| Webhook idempotency | Implement UUID-based deduplication in every webhook handler to prevent pipeline inconsistencies. |
| SLA scope matters | Ask vendors specifically whether transcoding failure rates and CDN delivery quality are covered. |
| Full-pipeline coverage | Unified platforms with end-to-end reliability reduce failure surface area versus multi-vendor stacks. |
| Production measurement | RUM at the player layer, not just server logs, is the only accurate source of reliability truth. |
The reliability metric nobody talks about
Most teams I work with arrive with the same blind spot: they treat their video API's HTTP success rate as a proxy for reliability, then wonder why users report problems the monitoring dashboard never caught. The gap is not a tooling problem. It is a definition problem.
The uncomfortable truth is that video reliability is a user-experience contract, not an infrastructure contract. When a transcoding job silently fails and the webhook never arrives, your API is technically "up." When a CDN edge node serves a stale manifest and the player loops on a spinner, your API is technically "up." These events do not appear in uptime calculations. They appear in churn data.
What I have found actually works is treating QoE metrics as the primary on-call signal. If rebuffer ratio spikes, that is your pager event, not a server error rate crossing a threshold. The second shift is designing for failure at the event layer from the start. Webhook ordering and deduplication are not edge cases to handle later. They are the default operating condition of distributed systems. Teams that build reliable webhook consumers from day one spend dramatically less time debugging phantom processing states six months later.
The vendors worth trusting are the ones who publish QoE benchmarks alongside uptime numbers, specify the load conditions of their SLA tests, and give you contractual commitments on transcoding reliability, not just endpoint availability.
— Alexandre
How Tornadoapi handles reliability at production scale
Tornadoapi is built for teams where extraction failure is not an option. The platform delivers 300 TB per month at 99.998% extraction reliability measured in production, with 50 Gbps capacity and direct cloud delivery to S3, R2, GCS, and Azure. Anti-bot handling and proxy rotation are managed infrastructure, not a toolbox your team maintains. For AI labs, transcription SaaS, and podcast platforms that need a contractual SLA on reliability rather than a collection of scripts to debug, Tornadoapi replaces fragile multi-vendor stacks with one API call and one accountability layer. Explore production-scale extraction plans or review the direct cloud export API to see how delivery reliability is architected at the infrastructure level.
FAQ
What does video API reliability mean in simple terms?
Video API reliability means the consistent delivery of stable video playback and accurate processing outcomes from ingest through delivery, measured by QoE metrics like startup success rate and rebuffer ratio rather than server uptime alone.
How is video API reliability different from standard API reliability?
Standard API reliability measures HTTP availability and error rates. Video API reliability adds viewer-centric metrics: time to first frame, rebuffering frequency, transcoding success rate, and webhook delivery accuracy across the full processing pipeline.
What is a good rebuffer ratio for a video API?
A rebuffer ratio below 0.5% is a common SLO target in streaming engineering. This metric measures total stall time divided by total watch time per session and directly correlates with user satisfaction and session abandonment.
Why does 99.9% uptime still allow significant video failures?
A 99.9% uptime SLA permits approximately 8.7 hours of downtime per year and typically covers only API endpoint availability. Transcoding pipeline failures, CDN delivery degradation, and webhook delivery gaps are not included in most vendor uptime calculations.
What should developers check when evaluating a video API's reliability claims?
Ask whether the SLA covers transcoding failure rates and CDN delivery quality, not just endpoint availability. Request benchmark data specifying the concurrent load conditions under which uptime figures were measured, and confirm whether webhook delivery guarantees are contractual.