
The Role of Anti-Bot Systems in Video APIs
Anti-bot systems are not just walls around content. They are multi-layered behavioral engines that actively reshape how video APIs perform under programmatic access. If you are building a video extraction pipeline, a transcription service, or an AI training dataset, understanding the role of anti-bot systems in video APIs is the difference between a reliable production system and one that silently fails at 2 a.m. This guide breaks down exactly how these systems detect automated clients, what they do to your extraction pipeline, and how you build around them without cutting corners.
Table of Contents
- Key Takeaways
- How anti-bot systems work in video APIs
- Challenges anti-bot systems create for video extraction
- Technical strategies for minimizing anti-bot impact
- Comparing major anti-bot platforms for video contexts
- Managing quotas and anti-bot signals in production
- My honest take on where this is all heading
- How Tornadoapi handles this for you
- FAQ
Key Takeaways
| Point | Details |
|---|---|
| Anti-bot systems use layered detection | Browser fingerprinting, TLS signatures, behavioral modeling, and IP reputation all feed a single risk score. |
| Behavioral models analyze full sessions | Detection happens across the session, not per request, making request-level evasion ineffective. |
| Session affinity prevents token invalidation | Sticky IPs and consistent fingerprints are required to keep signed manifest tokens valid throughout extraction. |
| API quotas require proactive management | Rotating API keys and reserving quota buffers prevents extraction pipeline outages from daily limit exhaustion. |
| Infrastructure-level solutions reduce friction | Delegating anti-bot handling to specialized infrastructure reduces engineering overhead and improves reliability SLAs. |
How anti-bot systems work in video APIs
Most developers assume anti-bot protection means CAPTCHAs. That assumption costs you weeks of debugging. Modern systems are far more subtle. APIs attract 44% of advanced bot traffic despite representing only 14% of the attack surface, which is exactly why platforms invest heavily in detection layers you never see.
The detection stack operates across several simultaneous dimensions:
- Browser fingerprinting. Canvas rendering output, WebGL renderer strings, installed fonts, screen resolution, and navigator properties are aggregated into a fingerprint hash. Any inconsistency between these signals and the declared User-Agent triggers an elevated risk score.
- TLS fingerprinting. The ClientHello message your HTTP stack sends contains cipher suites, extensions, and elliptic curves that identify the actual client library. A TLS fingerprint mismatch between your HTTP client and the browser you claim to be causes immediate blocking on platforms running Cloudflare, Akamai, or Kasada.
- IP and network reputation. Datacenter IP ranges, known proxy ASNs, and previously flagged addresses carry negative reputation scores before a single request completes.
- Behavioral modeling. Session-level behavioral analysis monitors mouse movement patterns, scroll velocity, keystroke timing, and navigation sequences over time. A bot that fires requests with perfect timing regularity stands out instantly against real user distributions.
- Honeypot traps. Invisible honeypot elements embedded in page markup or API responses are never interacted with by real users. Automated scripts that follow all links or fill all form fields trigger these traps immediately.
The result is a machine learning risk score that combines all of these signals. Roughly 80 to 90% of legitimate users pass without any visible challenge. CAPTCHAs only appear when the risk score sits in an ambiguous zone. For automated video extraction, you almost never get a CAPTCHA. You get a silent 403, a stripped response, or a poisoned manifest.
The distinction between "blocked" and "degraded" matters enormously in video API contexts. A degraded response that serves partial or incorrect data is far harder to detect in a pipeline than an outright block.
Challenges anti-bot systems create for video extraction
Understanding detection is half the problem. Understanding what those systems actually do to your workflow is the other half.
Rate limiting and quota enforcement are the most straightforward anti-bot mechanisms, but they compound quickly at scale. The YouTube Data API v3 enforces a 10,000 unit daily quota with per-second burst controls layered on top. Exceeding burst limits without backoff returns a 429 before you come close to the daily ceiling. Most pipelines hit burst limits, not daily quotas, during peak parallel extraction.

The more dangerous challenge is behavioral enforcement at the session level. Anti-bot systems do not evaluate individual HTTP requests in isolation. They evaluate the sequence, timing, and context of everything that session has done. A session that jumps from metadata fetching to manifest requests to segment downloads in sub-second intervals looks nothing like a real viewer. The platform does not necessarily block that session immediately. It degrades it: serving manifests with shorter expiration windows, silently throttling segment delivery, or invalidating tokens mid-extraction.
Here is the specific sequence that breaks most extraction pipelines:
- Your client fetches a video page or API endpoint and receives a signed playback token.
- The token is bound to the session fingerprint and IP address at issuance.
- Your pipeline switches to a different proxy or rotates the fingerprint for the next request.
- The platform detects the fingerprint or IP change mid-session and invalidates the token.
- The segment download returns a 403 with no clear error message about the root cause.
Session-bound ephemeral tokens require strict session affinity throughout the entire extraction sequence, from initial page load through the final segment download. Breaking that chain at any point restarts the risk scoring for that session from scratch.
Headless browser detection adds another layer. Tools like Playwright and Puppeteer expose "navigator.webdriver` and exhibit GPU rendering pipeline differences that platforms detect reliably. Headless browsers are detectable through rendering artifacts that headful browsers running in a virtual display do not produce.
Pro Tip: When your pipeline starts returning 403 errors on segment requests but not on manifest requests, the root cause is almost always token invalidation from broken session affinity, not IP blocking.
Technical strategies for minimizing anti-bot impact
Getting reliable extraction at scale requires building around the detection stack, not trying to overpower it. These are the approaches that actually work in production.
- Implement token bucket rate limiting with exponential backoff. Do not poll until you hit a 429. Calculate your burst ceiling from observed response headers and stay 15 to 20% below it. When a 429 does appear, back off with jitter: randomized wait intervals prevent synchronized retry storms across parallel workers.
- Use headful browsers with virtual display for token extraction. Chromium running in a headful mode under Xvfb produces rendering artifacts that match real user sessions. Headful browser setups improve stealth at the cost of higher CPU and memory overhead, which is an acceptable tradeoff for token acquisition steps.
- Maintain TLS fingerprint coherence. Patch your HTTP client's TLS stack or use a library that correctly mimics a target browser's ClientHello. Libraries like
curl-impersonateor browser-native fetch APIs handle this. Mismatched TLS signals are one of the fastest detection triggers across all major platforms. - Enforce session affinity end-to-end. Assign a sticky residential IP to each session at start and hold it through completion. Maintain a cookie jar and a consistent navigator fingerprint across the entire session. Do not reuse sessions across unrelated extraction tasks.
- Rotate proxies at session boundaries, not within them. Use residential IPs for initial page loads and token acquisition. Datacenter IPs can serve segment downloads where session tokens are already validated. Mobile IPs are useful for platforms with stricter geographic detection.
- Simulate behavioral realism where it matters. Advanced behavioral simulation uses Bézier curve mouse trajectories, natural typing rhythms with overshoot correction, and scroll inertia. You do not need this for every request, but you do need it during the interactive steps that generate session tokens.
- Never attempt DRM or license server bypass. Beyond being a legal risk, it triggers detection systems specifically tuned to identify Widevine and FairPlay tampering. DRM bypass attempts carry significant legal exposure under both DMCA and platform terms of service.
Pro Tip: Use short-lived scoped playback tokens per viewer session rather than long-lived credentials. This reduces exposure if a session is flagged and limits token reuse that anti-bot systems specifically look for.
Comparing major anti-bot platforms for video contexts
Not all anti-bot systems behave the same way. Knowing what you are up against shapes your countermeasure stack.
| Platform | Primary detection method | CAPTCHA behavior | Key fingerprints targeted | Programmatic solver support |
|---|---|---|---|---|
| Cloudflare Bot Management | Behavioral + JS challenge | Turnstile (usually invisible) | TLS, canvas, navigator | Moderate, token extraction feasible |
| Akamai Bot Manager | Sensor data + behavioral | Rare, mostly silent blocks | Sensor payload, timing, TLS | Difficult, sensor replay required |
| Kasada | JS polygraphy + behavioral | None visible, silent 429 | JS environment integrity | Very difficult, polygraphy obfuscated |
| DataDome | Behavioral + device | Modal CAPTCHA on escalation | Canvas, WebGL, timing | Moderate with headful browser pools |
| PerimeterX (HUMAN) | Behavioral + JS | CAPTCHA on high risk | Canvas, WebGL, navigator | Moderate, patching feasible |
The core distinction is between systems that rely on JavaScript environment integrity checks (Kasada, Akamai) and systems that weight behavioral signals more heavily (DataDome, PerimeterX). JS integrity systems are nearly impossible to defeat with patching alone because they hash the entire execution environment. Behavioral systems are addressable with realistic session simulation.
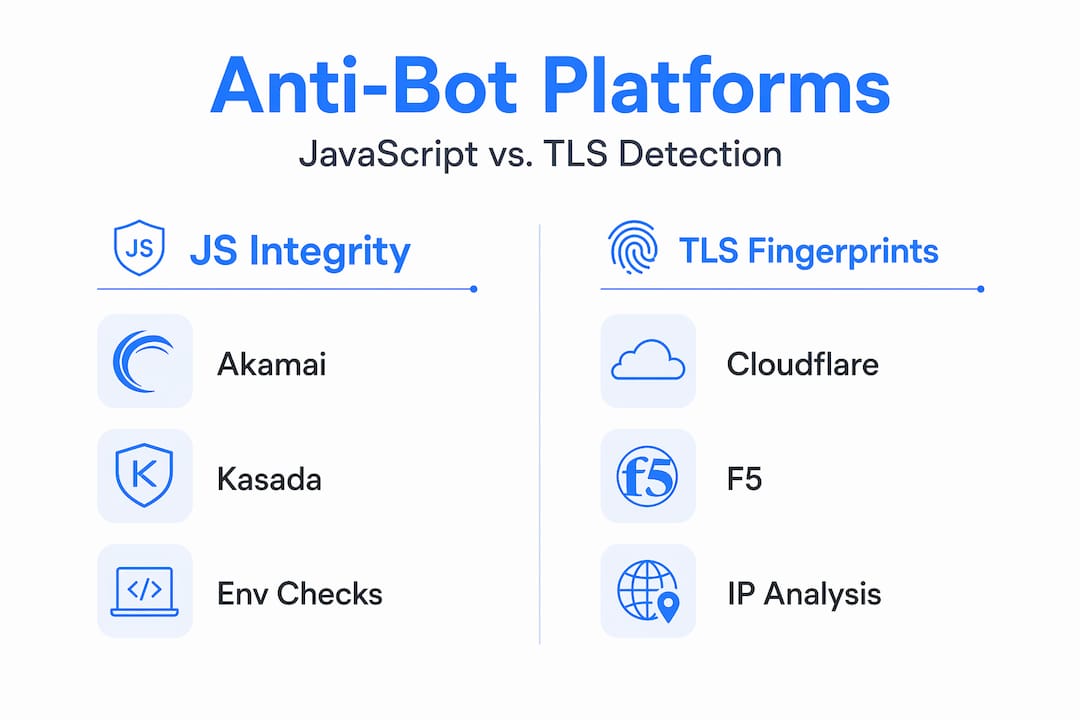
For video API contexts specifically, Akamai and Kasada appear most frequently on large media platforms and CDN-backed streaming infrastructure. Cloudflare is common on mid-tier video platforms and content aggregators.
Managing quotas and anti-bot signals in production
A production video extraction pipeline needs more than evasion tactics. It needs operational discipline around quota management and real-time signal monitoring.
- Track quota consumption per API key in real time. Do not wait for a 429 to discover you have exhausted the daily quota limit. Instrument every response to count units consumed and project remaining capacity against your extraction schedule.
- Rotate API keys before hitting the ceiling. Maintain a key pool and rotate based on usage thresholds, not failures. Reserving a 15% buffer per key prevents cascade failures when extraction demand spikes unexpectedly.
- Implement circuit breakers on 403 and 429 error rates. When a worker's error rate exceeds a threshold over a rolling window, open the circuit and reroute traffic to a clean session before the platform escalates that IP or fingerprint to a longer-duration block.
- Use conditional requests to reduce quota consumption. ETags and
If-Modified-Sinceheaders let you skip full response payloads for content that has not changed. This is particularly useful for metadata fetching in bulk catalog workflows. - Run proactive proxy health checks. Test each proxy IP against your target platform before assigning it to an active session. A proxy that returns a CAPTCHA page on the health check will invalidate your session token before you extract a single segment.
- Log challenge page frequency alongside standard error codes. A rising rate of challenge pages that resolve to 200 responses is an early warning that your behavioral profile is drifting toward detection thresholds.
Pro Tip: Prefer the cheapest API endpoints that serve your data needs. On the YouTube Data API, list operations cost 1 unit while search costs 100. Restructuring your query strategy around cheaper endpoints can extend your effective daily capacity by an order of magnitude.
My honest take on where this is all heading
I have watched extraction pipelines degrade from reliable to fragile in the span of a single platform update. The teams that struggle most are the ones who built their evasion stack once and assumed it would hold. It does not hold. Anti-bot systems ship updates continuously, and behavioral detection models retrain on new bot traffic patterns regularly.
What I have learned managing large-scale extraction under hostile anti-bot regimes is that session realism beats cleverness every time. The teams that win are not the ones with the most sophisticated fingerprint patches. They are the ones whose sessions look indistinguishable from real users at the session level, not just the request level. That requires investing in behavioral simulation, proper session lifecycle management, and proxy infrastructure that costs money.
The legal boundary is also not where most developers think it is. DRM is a clear line. But terms of service violations create real operational risk even when the technical barrier is crossable. I have seen platforms respond to systematic extraction by rotating their token signing keys on a schedule specifically calibrated to break pipelines that do not maintain session affinity. That is not a technical accident. It is a deliberate countermeasure.
My actual recommendation: use official API contracts where they exist, layer extraction infrastructure only for data that has no licensed pathway, and build your pipeline on infrastructure with a real SLA rather than a collection of open-source tools you maintain yourself. The engineering time you save is not marginal. It is the difference between a team that ships product and a team that maintains a bot arms race.
— Alexandre
How Tornadoapi handles this for you
Tornadoapi sits between your pipeline and platforms like YouTube, TikTok, Instagram, and Spotify. Every extraction call you make goes through anti-bot handling, proxy rotation, session management, and format normalization on our side. Your team writes one API call. We ship the file to your S3, R2, GCS, or Azure bucket. We deliver 300 TB per month at 99.998% extraction reliability, which is a contractual SLA, not a marketing claim. If you are building a video clipping platform or running bulk extraction for an AI training dataset, explore our production-scale plans or book an infra-to-infra call at cal.com/velys/30min.
FAQ
What is the role of anti-bot systems in video APIs?
Anti-bot systems in video APIs enforce rate limits, validate session integrity, and use behavioral modeling to distinguish automated clients from real users. They directly affect extraction reliability by invalidating tokens, throttling segment delivery, and silently blocking sessions that deviate from expected behavior patterns.
How do anti-bot systems detect video API scrapers?
They combine TLS fingerprinting, browser environment checks, IP reputation scoring, and session-level behavioral analysis. A TLS mismatch or irregular request timing pattern is often enough to elevate the risk score and trigger token invalidation or silent blocking.
Why do video API tokens expire mid-extraction?
Token invalidation mid-extraction almost always traces back to broken session affinity. Ephemeral playback tokens are bound to the IP and fingerprint present at issuance. Switching proxies or altering the fingerprint during a session causes the platform to invalidate the token immediately.
What HTTP error codes indicate anti-bot intervention in video APIs?
A 429 status indicates rate limiting or burst cap enforcement. A 403 status during segment download, especially after a successful manifest fetch, typically signals token invalidation from session affinity failure or fingerprint detection, not a permissions issue.
How can developers reduce the impact of bots on video APIs in their pipelines?
The most effective approach combines sticky IP session management, realistic behavioral simulation, TLS fingerprint coherence, and proactive quota monitoring. Delegating these layers to specialized extraction infrastructure like Tornadoapi removes the ongoing maintenance burden and provides contractual reliability guarantees.